Text-to-image synthesis generates images from natural language descriptions. You imagine some scenery or action, describe it through text, and then the AI generates the image for you from scratch. The image is unique and can be thought of as a window into machine ‘creativity’, if you can call it that. This field is still in its infancy and while previously such models were buggy and not all that impressive, the state of the art recently showcased by researchers at OpenAI is simply stunning. Frankly, it’s also a bit scary considering the abuse potential of deepfakes.
Imagine “a surrealist dream-like oil painting by Salvador Dali of a cat playing checkers”, “a futuristic city in synthwave style”, or “a corgi wearing a red bowtie and purple party hat”. What would these pictures look like? Perhaps if you were an artist, you could make them yourself. But the AI models developed at OpenAI, an AI research startup founded by Elon Musk and other prominent tech gurus, can generate photorealistic images almost immediately.
The images featured below speak for themselves.
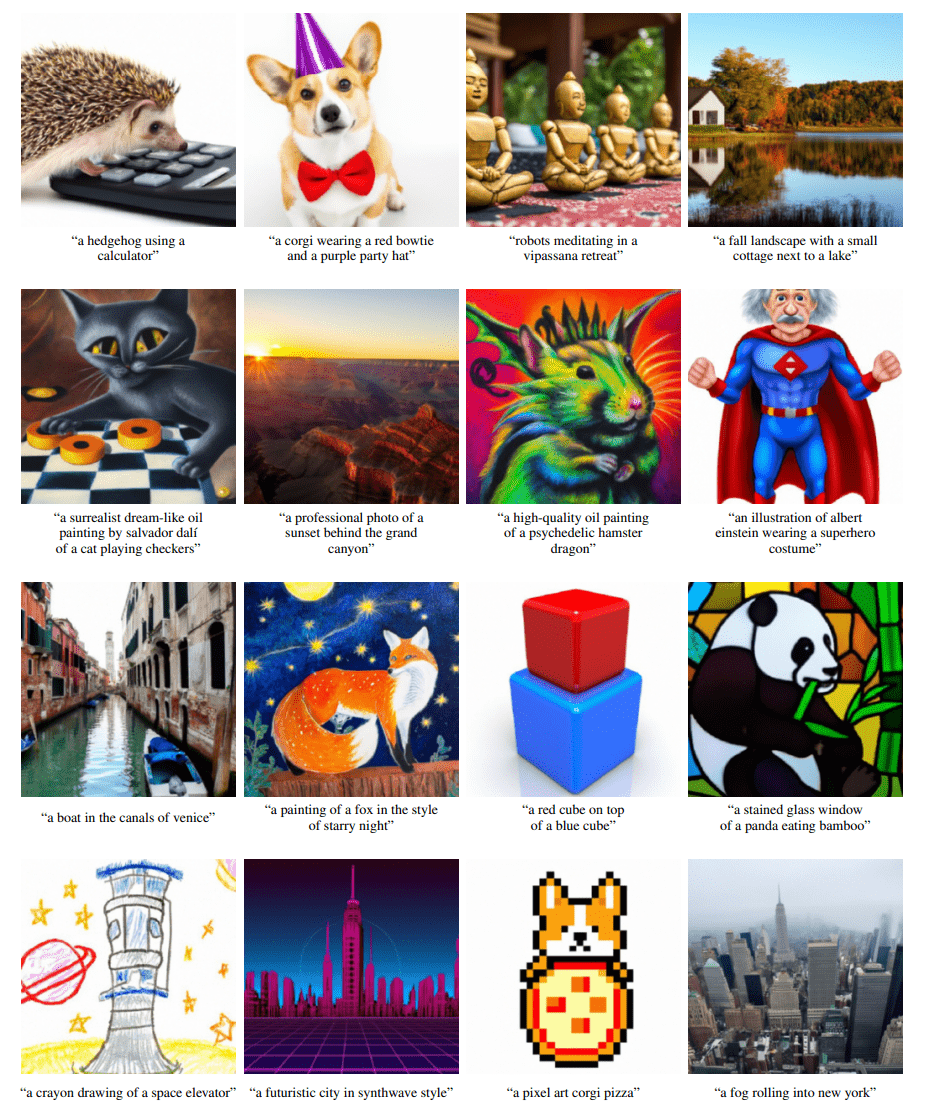
“We observe that our model can produce photorealistic images with shadows and reflections, can compose multiple concepts in the correct way, and can produce artistic renderings of novel concepts,” wrote the researchers in the pre-print server arXiv.
In order to achieve photorealism from free-form text prompts, the researchers applied guided diffusion models. Diffusion models work by corrupting the training data by progressively adding Gaussian noise, slowly wiping out details in the data until it becomes pure noise, and then training a neural network to reverse this corruption process. Their advantage over other image synthesis models lies in their high sample quality, resulting in images or audio files that are almost indistinguishable from traditional versions to human judges.
The computer scientists at OpenAI first trained a 3.5 billion parameter diffusion model that contains a text encoder to condition the image content on natural language descriptions. Next, they compared two distinct techniques for guiding diffusion models towards text prompts: CLIP guidance and classifier-free guidance. Using a combination of automated and human evaluations, the study found classifier-free guidance yields the highest-quality images.
While these diffusion models are perfectly capable of synthesizing high-quality images from scratch, producing convincing images from very complex descriptions can be challenging. This is why the present model was equipped with editing capabilities in addition to “zero-shot generation”. After introducing a text description, the model looks for an existing image, then edits and paints over it. Edits match the style and lighting of the surrounding content, so it all feels like an automated Photoshop. This hybrid system is known as GLIDE, or Guided Language to Image Diffusion for Generation and Editing.
For instance, inputting a text description like “a girl hugging a corgi on a pedestal” will prompt GLIDE to find an existing image of a girl hugging a dog, then the AI cuts the canine from the original image and pastes a corgi.

Besides inpainting, the diffusion model is able to produce its own illustrations in various styles, such as the style of a particular artist, like Van Gogh, or the style of a specific painting. GLIDE can also compose concepts like a bowtie and birthday hat on a corgi, all while binding attributes, such as color or size, to these objects. Users can also make convincing edits to existing images with a simple text command.

Of course, GLIDE is not perfect. The examples posted above are success stories, but the study had its fair share of failures. Certain prompts that describe highly unusual objects or scenarios, such as requesting a car with triangle wheels, will not produce images with satisfying results. The diffusion models are only as good as the training data, so imagination is still very much in the human domain — for now at least.
The code for GLIDE has been released on GitHub.


