
Most large-scale simulations are of specific processes, such as star formation, galaxy merges, our solar system events, the climate, and so on. These aren’t easy to simulate at all — they’re complex displays of physical phenomena which are hard for a computer to add all the detailed information about them.
To make it even more complicated, there are also random things happening. Even something simple like a glass of water is not exactly simple. For starters, it’s never pure water, it has minerals like sodium, potassium, various amounts of air, maybe a bit of dust — if you want a model of the glass of water to be accurate, you need to account for all of those. However, not every single glass of water will contain the exact same amount of minerals. Computer simulations need to try their best to estimate the chaos within a phenomenon. Whenever you add more complexity, the longer it takes to complete the simulation and the more processing and memory you need for it.
So how could you even go about simulating the universe itself? Well, first of all, you need a good theory to explain how the universe is formed. Luckily enough, we have one — but it doesn’t mean it’s perfect or that we are 100% sure it is the correct one — we still don’t know how fast the universe expands, for example.
Next, you add all the ingredients at the right moment, on the right scale – dark matter and regular matter team up to form galaxies when the universe was around 200-500 million years old.
N-body simulations
Universe simulations are made by scientists for multiple reasons. It’s a way to learn more about the universe, or simply to test a model and confront it with real astronomical data. If a theory is correct, then the structure formed in the simulation will look as realistic as possible.
There are different types of simulations, each with its own use and advantages. For instance, “N-body” simulations focus on the motion of particles, so there’s a lot of focus on the gravitational force and interactions.
The Millenium Run, for instance, incorporates over 10 billion dark matter particles. Even without knowing what dark matter really is, researchers can use these ‘particles’ to simulate dark matter properties. There were other simulations, such as IllustrisTNG, which offers the capability of star formation, black hole formation, and other details. The most recent one is a 100-terabyte catalog.
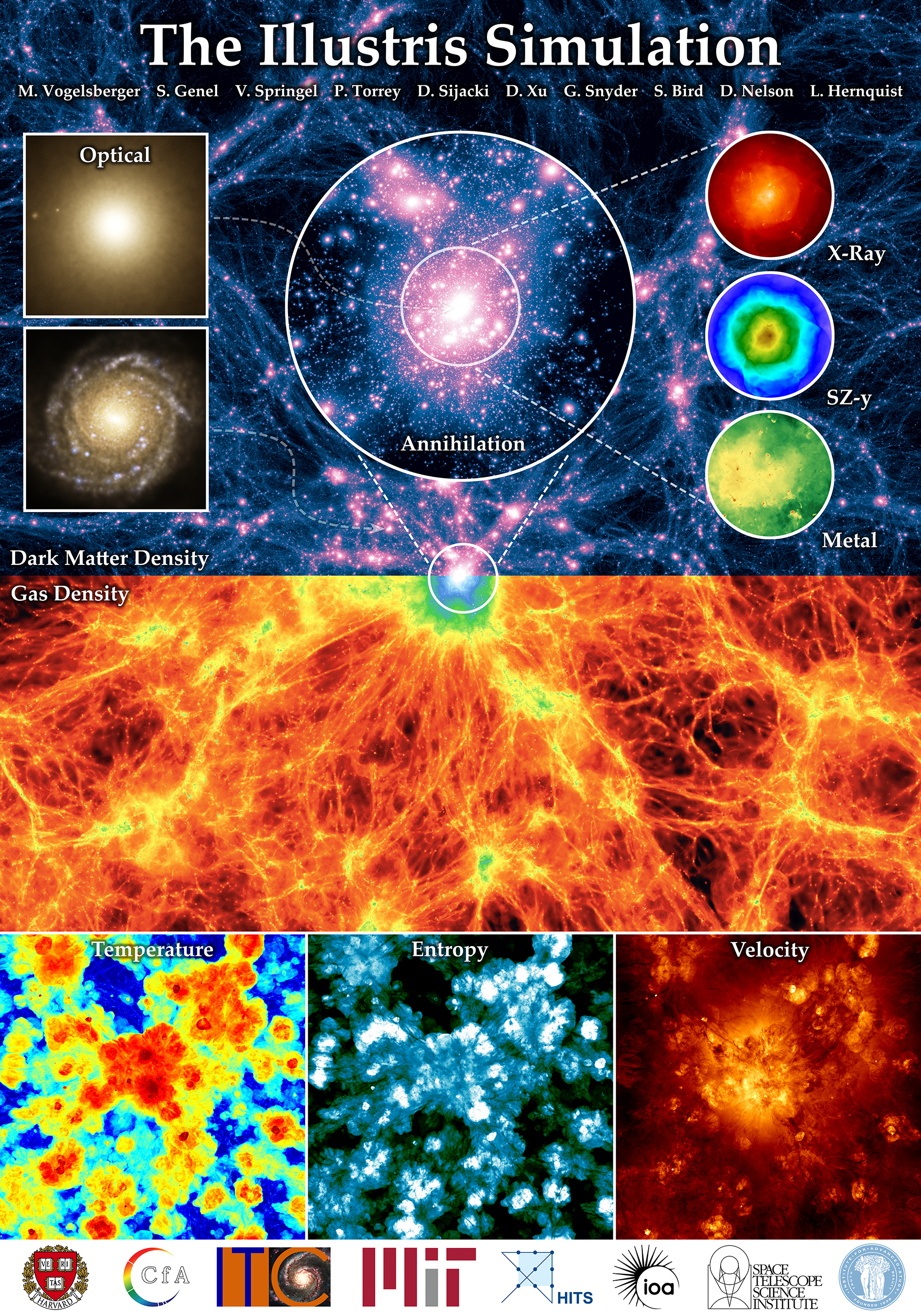
In the end, the simulations can’t reveal every single detail in the universe. You can’t simulate what flavor pie someone is having, but you can have enough detail to work with large-scale things such as the structure of galaxies and other clusters.
Mock Catalogs
Another type of model is a mock catalog. Mocks are designed to mimic a mission and they use data gathered by telescopes over years and years. Then, a map of some structure is created — it could be galaxies, quasars, or other things.
The mocks simulate these objects just as they were observed, with their recorded physical properties. They are made according to a model of the universe, with all the ingredients we know about.
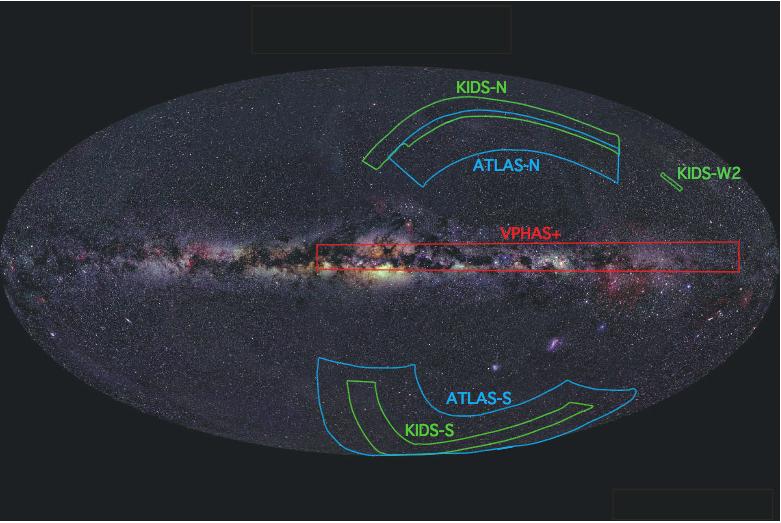
The theory from the model used for the mocks can be tested by comparing them with the telescopes’ observation. This gives an idea of how right or wrong our assumptions and theories are, and it’s a pretty good way to put ideas to the test. Usually, the researchers use around 1000 mocks to also give statistical significance to their results.
Hardware
Let’s take a look behind the scenes at how the models are produced — and how much energy they use. These astronomical and climate simulations are made on supercomputers, and they are super. The Millenium Run, for example, was made using the Regatta supercomputer. For these simulations, 1 terabyte of RAM was needed and resulted in 23 terabytes of raw data.
The IllustrisTNG used the Hazel Hen. This beast can perform at 7.42 quadrillion floating-point operations per second(Pflops), which is equivalent to millions of laptops working together. In addition, Hazel Hen consumes 3200 Kilowatts of energy — which leads to a spicy electric bill. Uchuu, which had 100 terabytes of results was made using ATENURI II. This one performs with 3.087 Pflops.
In an Oort Cloud simulation, the team involved reported the amount of energy they used in their work: “This results in about 2MWh of electricity http://green-algorithms.org/), consumed by the Dutch National supercomputer.” A habit that may become more common in the future.
Simulation Hypothesis
So what does this tell us about the possibility of our very own universe being a simulation? Could we be living in some sort of Matrix? Or just be in a Rick&Morty microverse? Imagine the societal chaos of figuring out we are in a simulated universe and you are not a privileged rich country citizen? That wouldn’t end well for the architect.
The simulation hypothesis is actually regarded seriously by some researchers. It was postulated by Nick Bostrom, and has three main conditions — at least one needs to be true:
(1) the human species is very likely to go extinct before reaching a “posthuman” stage;
(2) any posthuman civilization is extremely unlikely to run a significant number of simulations of their evolutionary history (or variations thereof);
(3) we are almost certainly living in a computer simulation.
ARE YOU LIVING IN A COMPUTER SIMULATION?
This being said, the simulation hypothesis is not a scientific theory. It is simply an idea — a very interesting one, but simply put, nothing more than an idea.
Lessons from simulations
What we learned from making our simulations is that it is impossible to make a perfect copy of nature. The N-body simulations are the perfect example, we can’t simulate everything, but the particles that make what is relevant to study. In climate models we have the same problem, it is impossible to create the perfect pixel to reproduce geographic locations, you can only approximate the desired features.
The other difficulty is energy consumption, it is hard for us to simulate some phenomena. Simulating a universe in which people make their own choices would require an improbable amount of power, and how could the data be stored. Unless it ends like Asimov’s ‘The Last Question’ — which is well worth a read.

In the end, simulations are possible, but microverses are improbable. We’ll keep improving simulations, making better ones in a faster supercomputer. All this with the thought that we need an efficient program, which consumes less energy and less time.







{kind=link}