A few months ago, researchers unveiled GPT-3 — the most advanced text-writing AI ever developed so far. The results were impressive: not only could the AI produce its own texts and mimic a given style, but it could even produce bits of simple code. Now, scientists at OpenAI which developed GPT-3, have added a new module to the mix.

Called DALL·E, a portmanteau of the artist Salvador Dalí and Pixar’s WALL·E, the module excerpts text with multiple characteristics, analyzes it, and then creates a picture of what it understands.
Take the example above, for instance. “An armchair in the shape of an avocado” is pretty descriptive, but can also be interpreted in several slightly different ways — the AI does just that. Sometimes it struggles to understand the meaning, but if you clarify it in more than one way it usually gets the job done, the researchers note in a blog post.
“We find that DALL·E can map the textures of various plants, animals, and other objects onto three-dimensional solids. As in the preceding visual, we find that repeating the caption with alternative phrasing improves the consistency of the results.”
Details about the module’s architecture have been scarce, but what we do know is that the operating principle is the same as with the text GPT-3. If the user types in a prompt for the text AI, say “Tell me a story about a white cat who jumps on a house”, it will produce a story of that nature. The same input a second time won’t produce the same thing, but a different version of the story. The same principle is used in the graphics AI. The user can get multiple variations of the same input, not just one. Remarkably, the AI is even capable of transmitting human activities and characteristics to other objects, such as a radish walking a dog or a lovestruck cup of boba.


“We find it interesting how DALL·E adapts human body parts onto animals,” the researchers note. “For example, when asked to draw a daikon radish blowing its nose, sipping a latte, or riding a unicycle, DALL·E often draws the kerchief, hands, and feet in plausible locations.”
Perhaps the most striking thing about these images is how plausible they look. It’s not just dull representations of objects, the adaptations and novelties in the images seem to bear creativity as well. There’s an almost human ambiguity to the way it interprets the input as well. For instance, here are some images it produced when asked for “a collection of glasses sitting on a table”.

The system uses a body of information consisting of internet pages. Each part of the text is taken separately and researched to see what it would look like. For instance, in the image above, it would look at thousands of photos of glasses, then thousands of photos of a table, and then it would combine the two. Sometimes, it would decide on eyeglasses; other times, drinking glasses, or a mixture of both.
DALL·E also appears capable of combining things that don’t exist (or are unlikely to exist) together, transferring traits from one to the other. This is apparent in the avocado-shaped armchair images, but is even more striking in the “snail made of harp” ones.

The algorithm also has the ability to apply some optical distortion to scenes, such as “fisheye lens view” and “a spherical panorama,” its creators note.
DALL·E is also capable of reproducing and adapting real places or objects. When prompted to draw famous landmarks or traditional food, it
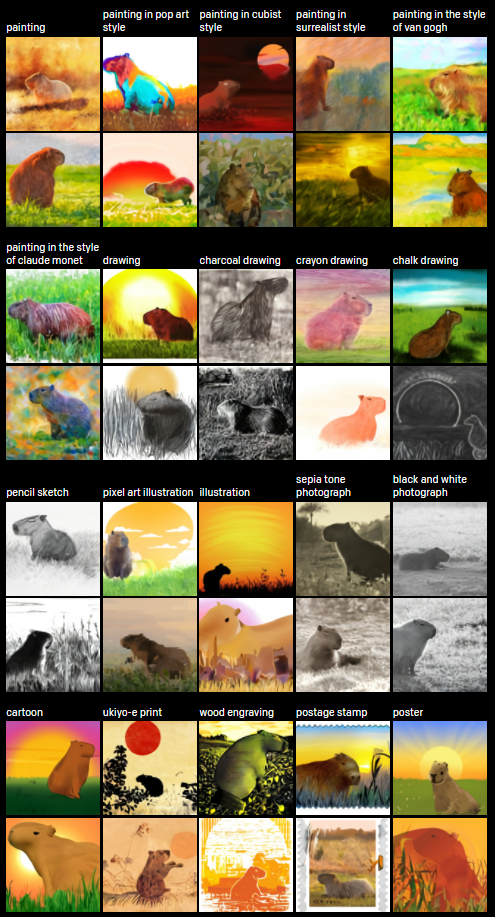
At this point, it’s not entirely clear what it could be used for. Fashion and design come to mind as potential applications, though this is likely just scratching the surface of what the module can do. Until further details are released, take a moment to relax with this collage of capybaras looking at the sunset painted in different styles.







{kind=link}